

I/O Parallelism(Data Partitioning)
Input/Output (I/O) parallelism is the simplest form of parallelism in which the relations (tables) are partitioned on multiple disks to reduce the retrieval time of relations from disk. In .I/O parallelism, the input data is partitioned and then each partition is processed in parallel. The results are combined after the processing of all partitioned data.
I/O parallelism is also called data partitioning.
Partitioning Techniques
The following four types of partitioning techniques can be used:
Type of Partitioning Techniques
- Hash Partitioning Techniques
- Round-Robin Partitioning Techniques
- Range Partitioning Techniques
- Schema Partitioning Techniques
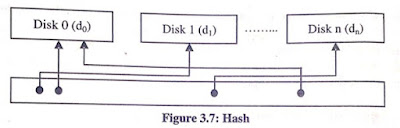
Hash Partitioning Techniques: With hash partitioning, Adaptive Server uses a hash function to specify the partition assignment for each row. You select the partitioning key columns, but Adaptive Server chooses the hash function that controls the partition assignment.
Range Partitioning: Rows in a range-partitioned table or index are distributed among partitions according to values in the partitioning key columns. Range partitioning is particularly useful for high-performance applications in both OLTP (Online Transaction Processing) and decision-support environments.
Round-Robin Partitioning: In round-robin partitioning, Adaptive Server does not use partitioning criteria. Roundrobinpartitioned tables have no partition key.

Schema Partitioning: In schema partitioning technique, different relations (tables) within a. database are placed n different disks.



