

Following are the key element of Parallel Database Processing:
1) Speed-up and Scale-up: Measure of the performance goals of parallel processing in terms of two important properties:
i) Speed-up: Speedup is the extent to which more hardware can perform the same task in less time than the original system. With added hardware, speedup holds the task constant and measures time savings. Figure 3.4 shows how each parallel hardware system performs half of the original task in half the time required to perform it on a single system.
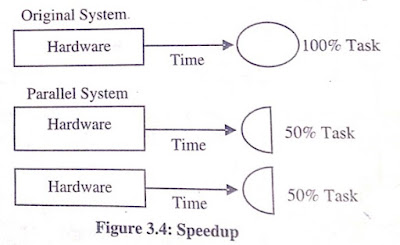
With good speedup. additional processors reduce system response time. One can measure speed-up using this formula:
Speedup = Time_Original/Time_Parallel.
Where, Time - Parallel is the elapsed time spent by a, parallel system on the same task
ii) Scale-up: Scale-up is the factor that expresses how much more work can be done in the same time period by a larger system. With added hardware, a formula for scale-up holds the time constant and measures the increased size of the job which can be done.
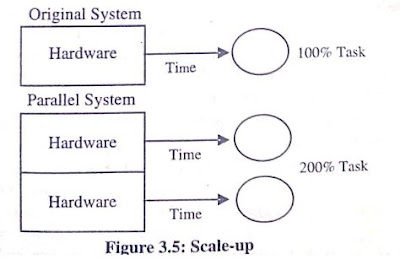
if transaction volumes grow and you have good scale-up, one can keep response time constant by adding hardware resources such as CPUs.
One can measure scale-up using this formula:
Scaleup = Volume_Parallel/Volume_Original
Where, Volume Parallel is the transaction volume processed in a given amount of time on a parallel system.
2) Synchronization: Co-ordination of concurrent tasks is called synchronization. Synchronization is necessary for correctness. The key to successful parallel processing is to divide tasks so very little synchronization is necessary. The less synchronization necessary, the better the speedup and scaleup.
In parallel processing among nodes, having a high-speed interconnect among the parallel processors is helpful. The overhead of this synchronization can be very expensive if a great deal of inter-node communication is necessary.
For parallel processing within a node, messaging is not necessary: shared memory is used instead. Messaging and locking between nodes is handled by the Integrated Distributed Lock Manager (IDLM).
The amount of synchronization depends on the amount of resources and the number of users and tasks working on the resources. Little synchronization may be needed to co-ordinate a small number of concurrent tasks, but significant synchronization may be necessary to co-ordinate many concurrent tasks.
3) Locking: Locks are resource control mechanisms that synchronize tasks. Many different types of locking mechanisms are required to synchronize tasks required by parallel processing.
The Integrated Distributed Lock Manager (Integrated DLM or IDLM) is the internal locking facility used with OPS. It co-ordinates resource sharing between nodes running on a parallel server and the instances of a parallel server use the IDLM to communicate with each other and co-ordinate modification of database resources. Each node operates independently of Other nodes, except when contending for the same resource.
The IDLM allows applications to synchronize access to resources such as data: software and peripheral devices. so concurrent requests for the same resource are co-ordinated among applications running on different nodes. The IDLM performs the following services for applications:
- Keeps track of the current "ownership" of a resource.
- Accepts lock requests for resources from application processes.
- Notifies the requesting process when a lock on a resource is available.
- Notifies processes blocking a resource that they should release or downgrade a lock.
- Obtains access to a resource for a process.
4) Messaging: Parallel processing performs best when one has fast and efficient communication among nodes. The optimal type of system to have is one with high bandwidth and low latency that efficiently communicates with the IDLM. Bandwidth is the total size of messages that can be sentper second. Latency is the time in seconds that it takes to place a message on interconnect and receive a response.
Most Massively Parallel Processor (MPP) systems and clusters have networks with reasonably high bandwidths. Latency, on the other hand. is an operating system issue that is mostly influenced by interconnect software and interconnect protocols. MPP systems and most clusters, characteristically use interconnects with high bandwidth .and low latency; other clusters may use Ethernet connections with relatively low bandwidth and high latency.



